Kysynnän tyydyttäminen tarjonnalla
Artikkelin otsikossa olevat kolme m-kirjaimella alkavaa sanaa ovat monelle tuttuja Mitä missä milloin – Kansalaisen vuosikirja -tietokirjasarjasta, jota on julkaistu jo vuodesta 1950 asti. Kirjasarjassa käsitellään kuluneen vuoden tapahtumia ja puheenaiheita.
Suositun kirjasarjan nimessä esitetyt kysymykset ovat merkityksellisiä tiedonnälän tyydyttämisen lisäksi myös vähittäis- ja tukkukaupan hankintaketjussa.
Ennen 60-lukua Suomessa oli enimmäkseen pieniä kulmapuoteja, liha- ja maitokauppoja sekä leipomoita. Sen jälkeen katukuvaan ilmestyivät pienet valintamyymälät, hieman myöhemmin hallimyymälät ja vähitellen supermarketit. Kauppapaikan ja valikoiman koosta riippumatta, mitä, missä ja milloin -kysymyksiä on pohdittu varmasti siitä asti, kun kulutushyödykkeitä on vaihdettu rahaan muodossa tai toisessa. Kaikkien myyjien ja kauppiaiden tavoite on viime kädessä vähintäänkin tyydyttää kysyntä oikeanlaisella tarjonnalla: mitä tuotteita pitää olla, missä ja milloin.
Käsittelimme aihetta ensimmäisessä artikkelissamme Tilataan niin paljon, että varmasti riittää.
M, m ja m ovat myös datan ulottuvuuksia
Kuin sattumalta, mitä, missä ja milloin ovat myös usein ulottuvuuksia (engl. dimensioita) tilaus-toimitusketjun hallinnan ja kysynnän ennustamisen järjestelmissä – tai tarkemmin ottaen niiden data-arkkitehtuurissa.
Datan synty
Kun kuluttaja ostaa tuotteen, myyntitapahtuma rekisteröityy kassajärjestelmään. Tapahtumasta syntyy asiakkaalle todisteena kuitti, jossa on eriteltynä rivitasolla mm. tuotteiden määrät, hinnat ja annetut alennukset.
Hieman kassajärjestelmästä ja mahdollisesti sen taustalla toimivasta toiminnanohjausjärjestelmästä riippuen, data tallentuu tietokantaan suurin piirtein samalla tarkkuudella, kuin miten se tulostuu kassakuitille. Jokainen kassakuitin rivi päätyy lopulta riviksi tietokantatauluun. Näitä rivejä kutsutaan usein transaktioiksi. Jotkin järjestelmät monistavat yksitäisen kassarivin useaksi eri tyyppiseksi transaktioksi, kuten varastotapahtuma- ja myyntitransaktio.
Kysynnän ennustamisen ja tarvelaskennan näkökulmasta ei ole väliä, minkä tyyppistä transaktiota tarkkaillaan, kunhan se sisältää riittävästi tietoa ja riittävällä tarkkuudella.
Datan esikäsittely
Jotta kassajärjestelmän tallentamaa kuittirividataa voitaisiin hyödyntää tehokkaasti, se kannattaa aggregoida järkevälle tasolle. Aggregointi on tilastotieteen termi, joka tarkoittaa tässä yhteydessä lukujen summaamista tai tapahtumamäärien laskentaa.
Järkevä aggregaattitaso kysynnän ennustamisessa on päivä – siis aikaulottuvuudessa (milloin). Muiden ulottuvuuksien, eli mitä ja missä järkevät aggregaattitasot ovat nimike ja toimipiste; arkisemmin tuote ja myymälä.
Kassajärjestelmän tuottamasta kuittirividatasta on siis tehokasta luoda merkityksellisiä ennusteaikasarjoja aggregoimalla se kolmiulotteiselle tasolle: nimike-toimipiste-päivä.
Modernit ja suorituskykyiset kysynnän ennustamisen järjestelmät aggregoivat edellä mainitulle tasolle valmiiksi jopa kymmeniä erilaisia arvoja, kuten kpl-myynti, eur-arvoinen myynti, kate, alennukset, hävikki, inventaarioerot, asiakasmäärä jne.
Datan hyödyntäminen
Aggregoinnin perimmäinen tarkoitus on nopeuttaa erilaisia taustalla tai käyttöliittymässä suoritettavia laskentatoimia, kuten kysynnän aikasarjaennustaminen tai keskiostos-aikasarjaraportin näyttäminen käyttöliittymässä. Jälkimmäisen esimerkin lukuja on mahdotonta laskea etukäteen, sillä lopputulos riippuu käyttäjän tekemistä rajauksista, mutta keskiostoksen laskukaavan nimittäjä ja osoittaja sen sijaan voidaan hyvinkin aggregoida toimipiste-nimike-päivä -tasolle.
Datan hyödyntäminen ja jatkokäsittely on tehokasta, kun se on esikäsitelty (aggregoitu) järkevästi. Edellisen kappaleen lopussa mainittujen arvojen lisäksi toimipiste-nimike-päivä -tasolle voidaan tallentaa laskennallisia arvoja ja analyysien tuloksia.
Esimerkiksi aikasarjaennuste, joka on laskettu aikaisemman kysynnän perusteella, kannattaa tallentaa samalle tasolle: toimipiste-nimike-päivä, jotta sen hyödyntäminen tarvelaskennassa tai vaikkapa näyttäminen visuaalisesti käyttöliittymässä rinta rinnan myynnin kanssa olisi nopeaa.
Toisena esimerkkinä mainittakoon saatavuusanalyysi, jonka tulokset voidaan niin ikään tallentaa jo tutuksi tulleelle aggregaattitasolle. Alla olevassa taulukossa on esimerkkiaikasarja yhden toimipiste-nimike -parin tilanteesta. Jokainen sarake vastaa yhtä toimipiste-nimike-päivä -tasoista tietuetta ja rivillä olevat arvot ovat kyseiselle tasolle tallennettuja (kaksi ylintä) tai laskennallisia/pääteltyjä arvoja (alin).

Tämän yksinkertaisen esimerkin tarkoituksena on havainnollistaa, että kun saatavuustieto on tallennettu valmiiksi oikealle aggregaattitasolle, sen jatkohyödyntäminen on nopeaa. Tuote on ollut saatavilla 9 päivänä 12:sta, jolloin se on ollut valikoimassa. Raportille voitaisiin tästä laskea, että saatavuus on tarkastelujaksona ollut 75% (9/12=0,75). Tarkemmin ottaen, saatavuus on Kyllä/Ei-aikasarjan keskiarvo olettaen, että Kyllä=1 ja Ei=0. Ilman datan esikäsittelyä, saatavuuden laskeminen olisi huomattavasti enemmän laskentatehoa ja aikaa vaativaa.
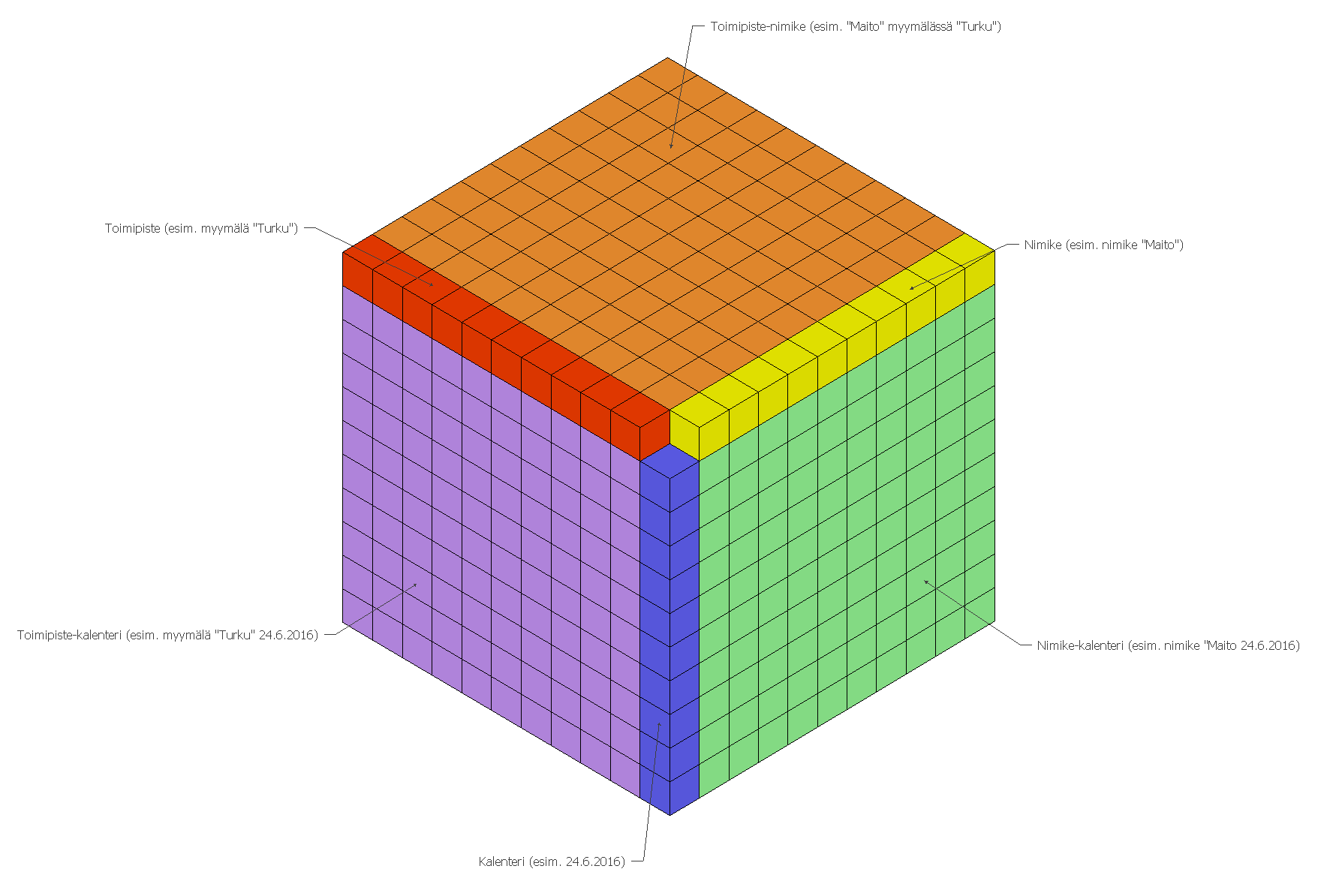
Kaikkien ulottuvuuksien kombinaatiot
Tässä artikkelissa on keskitytty kolmeen ulottuvuuteen: toimipiste-nimike-kalenteri. Alla oleva kuva havainnollistaa näitä ulottuvuuksia kuution muodossa. Punainen akseli on toimipiste, keltainen nimike ja sininen kalenteri (tai päivä).
Kaikki kuution sisällä piilossa olevat solut ovat toimipiste-nimike-kalenteri -tason tietueita, joita tässä artikkelissa on tähän asti käsitelty.
Oranssi, vihreä ja violetti osa, jotka jäävät ulottuvuusakselien väliin, ovat itseasiassa kaksiulotteisia tasoja: toimipiste-nimike, nimike-kalenteri ja toimipiste-kalenteri. Myös ne ovat hyödyllisiä aggregaattitasoja, joihin voidaan tallentaa hyödyllistä tietoa.
Esimerkiksi toimipiste-kalenteri -tasolle voidaan tallentaa tietoa, joka yhteistä kaikille nimikkeille kyseisessä toimipisteessä, mutta vaihtelee päivittäin: aukioloaika, säätila, henkilökunnan määrä jne.
Punaiset, keltaiset ja siniset solut ovat tietoa, jotka tulevat usein kysynnän ennustamisen järjestelmälle ”annettuna” taustajärjestelmästä (toimipiste- ja nimikerekisteri) tai ovat itsestään selviä (kalenteri).
Tieto ei lisää tuskaa
Edellä näkyvässä kuutiossa on 10x10x10 solua. Se voisi pitää sisällään 10 päivän osalta dataa myymäläketjusta, jossa on eri 10 tuotetta ja 10 myymälää.
Käytännönläheisempi esimerkki voisi olla 15 (myymälää) x 5000 (tuotetta) x 1095 (kolme vuotta päivissä) kokoinen kuutio, jonka sisällä on noin 82 miljoonaa solua. Kussakin solussa voisi olla muutamia kymmeniä aggregoituja arvoja ja erilaisten analyysien tuloksia. Riippuen tietokannan tarkemmasta rakenteesta ja indeksoinneista, tällainen määrä dataa tarvitsisi levytilaa kymmenisen gigatavua.
Modernille tietokantapalvelimelle ja -ohjelmistolle tällaisen tietomäärän säilöminen ja ylläpito on tuskatonta. Tiedon varsinainen käsittely ja laskenta voidaan suorittaa yöaikaan. Tieto ei siis lisää tuskaa. Sen sijaan on äärimmäisen tuskallista, jos tiedon näyttäminen käyttäjälle erilaisten raporttien muodossa tai sen hyödyntäminen liiketoiminnassa jollain muulla tavalla on hidasta.
Uusien teknologioiden, kuten osittain tai täysin muistinvaraisen tietokannan (In-Memory OLTP) hyödyntäminen yhdessä järkevän arkkitehtuurin kanssa vähentää tuskaa entisestään.
Lisätiedot
Supermind Oy on turkulainen teknologiayritys, joka on erikoistunut tilaus- ja toimitusketjun hallintaan liittyvien ohjelmistojen kehittämiseen ja myyntiin. SUPERMIND®-ohjelmistopalvelu sisältää ratkaisut valikoiman ja tuotteiden elinkaaren hallintaan, kysynnän ennustamiseen ja automaattisen täydennystilaamiseen.
SUPERMIND on Supermind Oy:n rekisteröity tavaramerkki.
Kiinnostuitko?
Näytämme mielellämme, miltä SUPERMIND näyttää livenä – ja miltä sen tuottamat tulokset näyttävät. Uskomme, että saamme vakuutettua teidät jo tunnin esittelyn aikana. Ota yhteyttä ja sovitaan tapaaminen!
Petri Lindholm
+358 400 420 583
[email protected]